
Es busquen milions de veus per ajudar les màquines a parlar català
El govern de Catalunya destinarà 3 milions d’euros al primer diccionari de veu en la llengua pròpia
El projecte col·laboratiu Common Voice ja té mil hores enregistrades
El vicepresident i conseller de Polítiques Digitals i Territori de la Generalitat de Catalunya, Jordi Puigneró, ha anunciat aquest dimarts que el govern destinarà tres milions d’euros aquest any al projecte Aina per tenir un corpus o “diccionari” de veu en català que pugui ser utilitzat perquè els assistents de veu ofereixin aquesta llengua.
Les veus s’obtindran a través de la plataforma Common Voice, que ha arribat a les 1.000 hores de veu enregistrades i a les 900 validades, segons ha anunciat Softcatalà.
L’objectiu, segons ha explicat Puigneró, és enregistrar “milions de veus” que han de servir per ensenyar català a les màquines perquè qualsevol empresa o organització les pugui fer servir per posar en marxa serveis com traductors o assistents de veu en català. El projecte Aina pretén que els parlants de català puguin participar en el món digital al mateix nivell que els d’una llengua global, com ara l’anglès.
Tothom qui vulgui participar en la campanya de recollida de veus La nostra llengua és la teva veu haurà de llegir i enregistrar un nombre il·limitat de frases (agrupades de 5 en 5 però sense límit) a la plataforma Common Voice. El procés es pot fer de manera totalment anònima i sense cap registre previ, però els impulsors del projecte remarquen que conèixer el gènere, edat i variant dialectal del “donant” de veu facilita molt la feina de classificar les dades obtingudes i permet saber si s’està tenint en compte tota la diversitat lingüística del català.
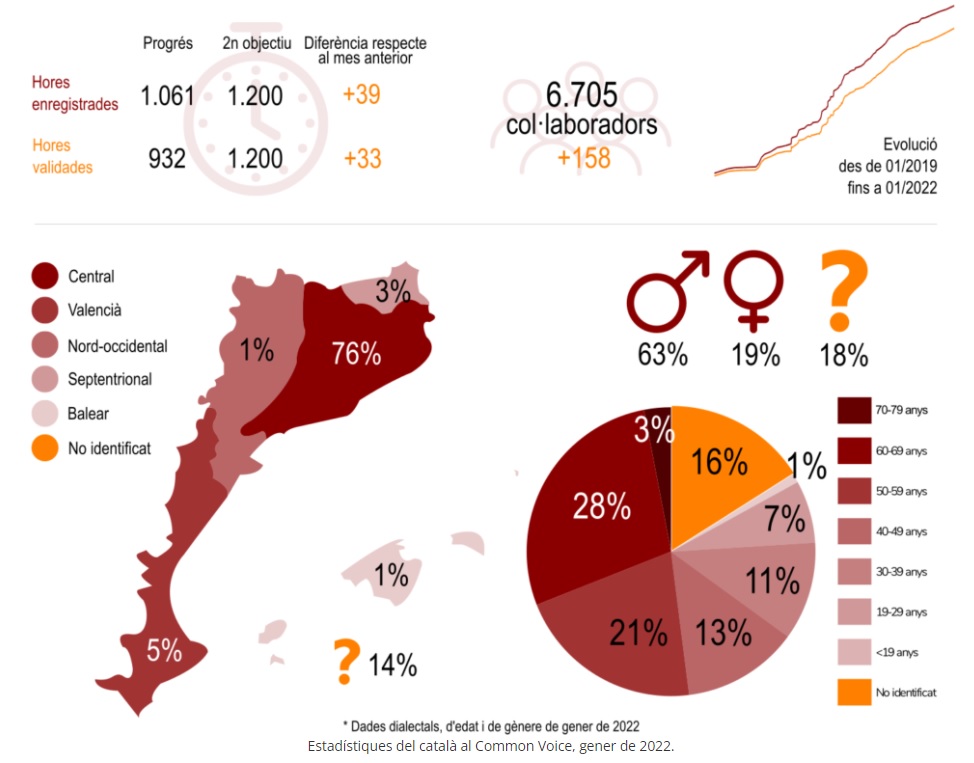
Les darreres dades sobre el català aportades per Common Voice revelen que hi ha un un important desequilibri pel que fa a les variants dialectals en les aportacions de veu. El català central suposa el 76% del volum de les donacions de veu, mentre que el valencià (5%), el nord-occidental (1%), el septentrional (3%) i el balear (1%) hi estan infrarepresentats. També hi ha un desequilibri important per gènere: el 63% de les aportacions són d’homes, el 19% dones i el 18% no identificades.
Les dades aportades pels voluntaris es passen a una xarxa neuronal profunda que va aprenent com es combinen les paraules fins a generar un model de la llengua capaç de distingir els diferents significats de paraules polisèmiques gràcies als diferents contextos en què es fa servir. Per construir el corpus de la llengua calen milions de textos i milions d’hores d’àudio i vídeo en aquella llengua i que representin persones de diferents gèneres, franges d’edat, variants dialectals i registres.
En el projecte hi col·laboren entitats com Softcatalà, universitats, l’Enciclopèdia Catalana, la Corporació Catalana de Mitjans Audiovisuals (CCMA) i ràdios locals. Puigneró mantindrà reunions amb els governs de la resta de territoris de parla catalana perquè se sumin a la campanya.